SEO og Python - Sådan automatiserer du de "umulige SEO-opgaver" (som konkurrenterne ikke kan overskue)
29. juli 2020
Der er SEO-opgaver, som bare er for tunge at håndtere manuelt.
Man kan hyre en billig indisk freelancer, eller man kan sætte den stakkels praktikant til at udføre den (og få sig en demotiveret medarbejder).
Alternativt – og det sker i de fleste tilfælde – så opgiver man på forhånd.
Men…
… man kan også automatisere opgaven med et Python script.
Dette blogindlæg handler om, hvordan du kan løse de “umulige SEO-opgaver” med hjælp fra Python. Vi deler vores erfaringer fra det sidste års tid med at løse de opgaver. Hvis du investerer din tid i at lære fra vores proces, får du unikke indsigter, som dine konkurrenter ikke kan overskue at finde frem til.
Jeg præsenterer dig bl.a. for vores innovative “thumbnail” løsning, som selveste Martin Splitt fra Google godkender.

HVAD ER UMULIGE SEO-OPGAVER?
Umulige SEO-opgaver er den type opgaver, der ikke er timer nok i døgnet til at lave manuelt, og de er typisk meget monotone.
Lad os tage et eksempel:
URL inspection tool i Google Search Console (søgebaren øverst i deres interface) giver dig unikke indsigter om, hvordan en URL på din side bliver set af Google.

Du kan ikke få denne viden fra andre værktøjer som Screaming Frog og Sitebulb.
Problemet er:
Hver eneste URL skal indsættes manuelt for at tjekke for fejl (suk). Hvad siger du til at få opgaven med at tjekke hundredevis af jeres URL’er manuelt?
En anden opgave kunne være, at du vil vide hvilke af dine søgeord, der ikke bliver vist et image thumbnail for på mobilen.
Eller hvad hvis du vil vide, hvilke søgeord der bliver vist rich snippets (som f.eks. FAQ eller kundeanmeldelser), og teste om der er indsat Schema markup, når de ikke bliver vist?
Dette er alle vigtige opgaver, som er umulige, hvis du har en manuel tilgang til dem.
Derfor kører vi i stedet Python scripts.
KLAR PÅ EN UDFORDRING?
Her er en udfordring til dig:
Hvor hurtigt kan du manuelt tjekke 100 URL’er i Google Search Consoles URL inspection tool? Hvis du er hurtigere end din skygge, så vil det tage dig 30 sek. at copy/paste hver enkelt URL ind i URL inspection tool og få resultatet.
Tidsforbrug: 50 min.
Ovre i det andet ringhjørne kører mit Python script. Jeg trykker return, og listen på de 100 URL’er kører igennem automatisk, mens jeg går ud og henter kaffe.
Tidsforbrug: 12 min. – Leveret i en CSV-fil.
Jeg fikser følgende fejl, mens jeg drikker min kaffe:
Det lyder lidt sjovere, ikke?
Så hvad er Python?
HVAD ER PYTHON?
![]()
Python er et platformsuafhængigt programmeringssprog tilgængeligt som open source. Ved at lave et script i Python kan jeg få computeren til at udføre forskellige opgaver. Den opgave, som vi fokuserer på her, er håndtering af repetitive opgaver med store datasæt. Python kan også bruges til import af data fra flere datakilder og at få diverse data til at tale sammen.
Kort sagt:
Python fjerner traditionelle tunge opgaver fra din manuelle to do liste, så du får frigivet tid til, at du kan fokusere på indsigter fremfor databehandling.
Hvis du er helt uerfaren med Python, så er Codecademy et godt sted at lære the basic. De har et glimrende gratis Python kursus. Med den viden kan du køre de scripts, som vi viser senere.
Der er kommet meget fokus på at bruge Python til SEO over de sidste år.
Dette skyldes specielt en mand.
Lad mig præsentere dig for Hamlet…

HAMLET BATISTA OG PYTHONREVOLUTIONEN
Hamlet Batista gik mainstream i SEO-miljøet efter hans forrygende talk til TechSEOBoost 2018 om at bruge Python til at løse praktiske SEO udfordringer. Du kan se hans talk på Youtube (starter ved 2:43).
Bonusinfo: Til sidst i præsentationen viser han, hvordan han ud fra Neil Patels tweets har trænet et neuralt network til at svare som Neil Patel, hvis nu Neil Patel en dag vælger at svare sine mange kritikere. Dejligt nørdet!
Et godt sted at starte er at læse Hamlets faste klumme på Search Engine Journal, hvor hans meget praktiske Python tutorials indlæg er nogle af de mest læste.
Vi bruger hyppigt hans scripts, som du også vil se i det følgende.
Men først:
PYTHON STARTER MED DET KRITISKE SPØRGSMÅL
Inden vi dykker ned i diverse scripts, så skal vi lige stoppe op.
Python er kun et værktøj. Ligesom når du bruger alle andre SEO-værktøjer, så må du ikke blive forblændet af mulighederne.
Du skal altid starte med det kritiske spørgsmål, som hænger sammen med jeres forretningsstrategi.
Hver eneste gang at vi bruger Python, så er det baseret på en kundespecifik situation, hvor vi ønsker at løse en konkret udfordring.
Når jeg bruger URL Inspection Tool i Google Search Console, er det fordi, at vores kunde kan vinde på Google ved at have et stærkt teknisk fundament, og den viden vi får er unik i fht. tredjepartsværktøjer.
Her får jeg direkte at vide fra Google:
– Er alle sider indekseret?
– Hvornår blev de sidst crawlet af Googlebotten?
– Er alle siderne mobilvenlige?
– Er Schema markup sat korrekt op?
– Har Google foretrukket den samme canonical version som os?
I brancher hvor vores kunder har meget mobiltrafik, og brugerne er visuelt orienteret (f.eks. modeindustrien og fitness), skal vi vinde på mobilen. Det kræver bl.a. fokus på at øge CTR. Udover klar kommunikation via title plus metabeskrivelse så er det vigtigt at vise et attraktivt image thumbnail. Derfor går vi den ekstra mil for at sikre os, at der altid bliver vist et image thumbnail.
Vi er så vidt jeg ved de første, som laver førnævnte type analyse, og jeg viser dig senere, hvordan I kan blive de næste.
TRE EKSEMPLER FRA EGNE RÆKKER PÅ BRUG AF PYTHON (+SCRIPTS)
Her får du tre praktiske eksempler, hvor vi har brugt Python til at løse kundespecifikke udfordringer. De er inddelt efter sværhedsgrad, så jeg vil anbefale, at du prøver eksempel 1 af først. Det andet eksempel kræver, at du har adgang til SEMRush, Ahrefs eller lignende – i det 3. eksempel skal du have adgang til Authoritas eller en anden dataleverandør:
EKSEMPEL 1 - AUTOMATISÉR URL INSPECTION TOOL
Jeg er vild med den nye version af Google Search Console.
En fed feature som nævnt tidligere i indlægget er URL inspection tool. Når jeg indsætter en URL, så hører jeg fra hestens egen mule om, hvordan Google ser min side.
Meget nyttige data, men det store problem er som sagt, at man manuelt skal indtaste én URL af gangen for at få resultatet.
Hvordan kan man automatisere denne proces og køre den ene URL efter den anden igennem? Med et Python script selvfølgelig. Du kan finde Hamlets originale script i denne artikel. Nedenfor får du vores modificerede script.
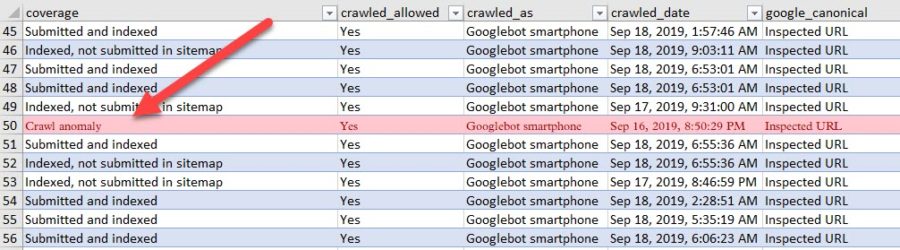
Vi har en kunde, som oplevede en del tekniske udfordringer. For at hjælpe deres tekniske leverandør med at finde fejlen kørte vi top 100 URL’er igennem.
Ouch!
Normalt ser det langtfra så slemt ud, men vi kan altid fange nogle vigtige indsigter.
Nedenfor gennemgår Poomika og jeg, hvordan man kører dette Python script i praksis, og hvordan det endelige resultat ser ud. Derefter får du scriptet, så du selv kan teste.
Download Hamlets GitHub repository her: https://github.com/ranksense/url-inspector-automator
1. Kør scriptet: requirements.txt ved at skrive: pip install -r requirements.txt
2. installér yderligere ved at skrive: python3 -m pip install -U git+https://github.com/miyakogi/pyppeteer.git@dev
3. Installér yderligere: pip3 install websockets==6.0 –force-reinstall
4. Kør scriptet: url_inspector_automator.py ved at skrive: python url_inspector_automator.py
from PyQt5 import QtCore, uic, QtWidgets
import sys, subprocess
import threading
import asyncio
from chrome_automator import ChromeAutomator
from urllib.parse import urljoin
import configparser
from jinja2 import Template
import pandas as pd
from time import sleep
#import pickle as pkl
from urllib.parse import urlparse
UIClass, QtBaseClass = uic.loadUiType(“url_inspector_automator.ui”)
class URLInspector(UIClass, QtBaseClass):
def __init__(self):
UIClass.__init__(self)
QtBaseClass.__init__(self)
self.setupUi(self)
self.chrome = [“C:/Program Files (x86)/Google/Chrome/Application/chrome.exe”,
“–remote-debugging-port=9222”, “–no-first-run”, “–user-data-dir={userFolder}”]
#connecting action buttons to corresponding methods/slots
self.commandLinkButton.clicked.connect(self.launchChrome)
self.pushButton.clicked.connect(self.inspectURLs)
self.pushButton_2.clicked.connect(self.exportResults)
#regenerate JS extractor
self.actionBox.currentTextChanged.connect(self.actionSelected)
self.auto = None # Chrome Automator placeholder
#load default selectors
selectors_ini = self.selectorsConf.text()
#print(selectors_ini)
self.config = configparser.ConfigParser()
self.config.read(selectors_ini)
print(“Selectors loaded”)
#convert config to JS files to inject into Chrome
self.generate_javascript_files()
self.headers = self.add_headers() #do once
self.results = list()
def add_headers(self):
#read columns from configuration file
data = list(self.config[“EXTRACTION”])
data.append(“url”)
self.resultsWidget.setColumnCount(len(data))
self.resultsWidget.setHorizontalHeaderLabels(data);
return data
def add_result(self, data):
rowPosition = self.resultsWidget.rowCount()
#insert empty row
self.resultsWidget.insertRow(rowPosition)
for i, column in enumerate(data.values()):
item = QtWidgets.QTableWidgetItem(column)
self.resultsWidget.setItem(rowPosition, i, item)
#resize table
self.resultsWidget.resizeColumnsToContents()
def add_no_indexed_urls(self):
#create pandas data frame with results
df = pd.DataFrame(self.results)
criteria = self.notIndexCriteria.text()
query = ‘coverage==”{criteria}”‘.format(criteria=criteria)
for url in df.query(query)[“url”]:
print(“This url: {url} is not indexed”.format(url=url))
self.urlsNotIndexed.insertPlainText(url+”\n”)
def generate_javascript_files(self):
#Javascript arrow function jinja2 template
with open(“js_extractor.jinja2”) as f:
template_text=f.read()
template=Template(template_text)
#combine template with relevant section in configuration file
self.extraction_fn = template.render(settings=self.config[“EXTRACTION”])
#Javascript arrow function jinja2 template
with open(“js_clicker.jinja2”) as f:
template_text=f.read()
template=Template(template_text)
self.clicking_fn = template.render(settings=self.config[“CLICKS”])
@QtCore.pyqtSlot()
def launchChrome(self):
#this prevents locking up the UI
threading.Thread(target=self.launchChromeThread, name=”_chrome”).start()
import time
#wait 5 seconds for Chrome
time.sleep(5)
print(“Output saved … reading WS URI”)
with open(“chrome.txt”, “r”) as chrome_output:
#with open(FIFO) as chrome_output:
lines = chrome_output.readlines()
if len(lines) > 0:
ws=lines[1].split()[3] #get WS URI
self.wsURI.setText(ws)
self.wsURI.setEnabled(False)
#enable inspectURLs
self.pushButton.setEnabled(True)
#disable launching Chrome
self.commandLinkButton.setEnabled(False)
#print(self.delay.text())
delay = int(self.delay.text())
self.auto = ChromeAutomator()
asyncio.get_event_loop().run_until_complete(self.auto.connect(ws, self.extraction_fn, self.clicking_fn))
def launchChromeThread(self):
# do something
print(“Launching Chrome Thread”) #
args = self.chrome
args[3] = args[3].format(userFolder=self.userFolder.text())
print(args)
with open(“chrome.txt”, “w+”) as chrome_output:
proc=subprocess.Popen(args, stderr=chrome_output)
#self.waitforChrome = False
# named slot
@QtCore.pyqtSlot()
def inspectURLs(self):
# do something
print(“Launched InspectURLs”) #
urls = self.urls2Check.toPlainText().split()
if len(urls) == 0:
QtWidgets.QMessageBox.about(self, “Inspect URLs”, “Please provide absolute URLs. For example: https://www.ranksense.com/”)
return
for url in urls:
if urlparse(url).netloc == “”:
QtWidgets.QMessageBox.about(self, “Inspect URLs”, “Please provide absolute URLs. For example: https://www.ranksense.com/”)
return
criteria = self.notIndexCriteria.text()
action = self.actionBox.currentText()
#inspect URL delay
delay = self.delay.text()
delay = int(delay)
#action delay
action_delay = self.delay_2.text()
action_delay = int(action_delay)
#comment below to debug without live Chrome
self.results = asyncio.get_event_loop().run_until_complete(self.auto.inspect_urls(urls, criteria, action, delay, action_delay))
print(“Done!”)
for data in self.results:
self.add_result(data)
#update not indexed
self.add_no_indexed_urls()
#enable exportResults
self.pushButton_2.setEnabled(True)
#enable submit URLs
self.urlsNotIndexed.setEnabled(True)
# named slot
@QtCore.pyqtSlot()
def actionSelected(self):
#update headers
self.add_headers()
#update generated js files
self.generate_javascript_files()
# named slot
@QtCore.pyqtSlot()
def exportResults(self):
#create pandas data frame with results
df = pd.DataFrame(self.results)
print(df[[“url”, “coverage”]].groupby(“coverage”).count())
df.to_csv(self.csvFile.text())
QtWidgets.QMessageBox.about(self, “Export Results”, “Successfully exported {count} URLs”.format(count=df.shape[0]))
if __name__ == “__main__”:
app = QtWidgets.QApplication(sys.argv)
window = URLInspector()
window.show()
sys.exit(app.exec_())
I næste eksempel ser vi på Rich snippets:
EKSEMPEL 2 - HVOR HAR VI RICH SNIPPETS GAPS?
Endnu et eksempel fra Hamlet, som han præsenterede på et Traffic Think Tank webinar.
Vi vil vide:
1. For hvilke søgeord bliver der vist rich snippets på side 1 på Google?
2. Men hvor vi ikke har Schema markup?
Hvis det var manuelt skulle vi Google hver eneste søgeord og notere hvilke SERP features der bliver vist. Derefter skulle vi manuelt køre hver af vores URL’er for disse søgeord igennem Googles URL structured data tester og identificere, hvilken Schema markup mangler – et kæmpe arbejde.
Vi bruger Python istedet.
Først trækker vi vores 500 vigtigste søgeord fra GSC.
Derefter kører vi dem igennem SEMRush for at identificere, hvilke SERP features, der bliver vist for hvert søgeord.
Nu skal vi køre hver eneste af vores URL’er for vores søgeord igennem Googles Testværktøj til Strukturerede Data. Som nævnt før så er det indsættelse af hver URL manuelt, men med Python kan det automatiseres med et Python script.
I modsætning til første eksempel så kan det godt tage 5-7 timer at køre det. Men som med alle andre Python scripts så kører det i baggrunden, mens du kan lave noget andet.
Vi merger vores CSV-fil fra Python scriptet med vores SEMRush data i Power BI og får følgende:

Hver række viser et søgeord, og den URL som søgeordet ranker på. Til højre for har vi syv kolonner med forskellige SERP features. Hvert markerede felt er en mulighed for at få vist en SERP feature. D.v.s., at bliver der vist video for det pågældende søgeord for et andet søgeresultat, og vi ikke har Video schema markup, så bør vi oprette og optimere en video for det søgeresultat.
Vore første levering af dette er stadig i implementeringsfasen. Men kunden har det fulde overblik over, hvornår de skal implementere de forskellige former for schema markup. Det der også er interessant her er, at selv hvis ingen af konkurrenterne får vist f.eks. FAQ markup i dag, men vi kan se, at typen af søgning passer til FAQ, så er der her en mulighed for at være first mover.
Dette er et rigtigt godt eksempel på en god løsning til en umulig SEO-opgave.
1. Opret en CSV-fil med en kolonne med alle dine udvalgte URL’er, som dine vigtigste søgeord ranker på.
2. Ret linje 10 i scriptet til filstien på CSV-filen, som lige er blevet oprettet.
3. Kør scriptet nedenfor: Scriptet tjekker, om URL’erne i CSV-filen indeholder strukturerede data. Scriptet spytter JSON data ud for hver enkelt URL, hvori man kan tjekke om URL’en indeholder syv forskellige Schema markup; image, video, local pack, review, top_story, FAQ og jobs.
4. Denne URL data holdes op mod vores søgeordsdata fra SEMRush (f.eks. i Power BI). Nu kan vi se, for hvilke søgeord at vi mangler SERP features på URL niveau. Mangler de, så skal de implementeres.
import extruct
import requests
import pprint
from w3lib.html import get_base_url
from csv import reader
import urllib.parse
import json
from jsonpath_ng import jsonpath, parse
with open(‘FILEPATH-TO-CSV-FILE-URL’, ‘r’, encoding=’utf-8-sig’) as read_obj:
# pass the file object to reader() to get the reader object
csv_reader = reader(read_obj)
# Iterate over each row in the csv using reader object
for row in csv_reader:
# row variable is a list that represents a row in csv
for row1 in row:
#print(row1)
pp=pprint.PrettyPrinter(indent=2)
r=requests.get(row1)
base_url=get_base_url(r.text,r.url)
data=extruct.extract(r.text,base_url=base_url)
#pp.pprint(data)
I det sidste eksempel vil vi vide følgende:
EKSEMPEL 3 - VISES ET IMAGE THUMBNAIL PÅ MOBILEN FOR MIT SØGEORD?
Efter først at have brugt Hamlets Python scripts, har vi nu udviklet vores egne for andre konkrete kundeudfordringer.
Her er en vigtig opgave fra egne rækker, som jeg nævnte i starten af indlægget:
Hvordan vil du identificere, hvilke hundredevis af søgeord, som ikke får vist et thumbnail i det organiske søgeresultat, som i eksemplet nedenfor?
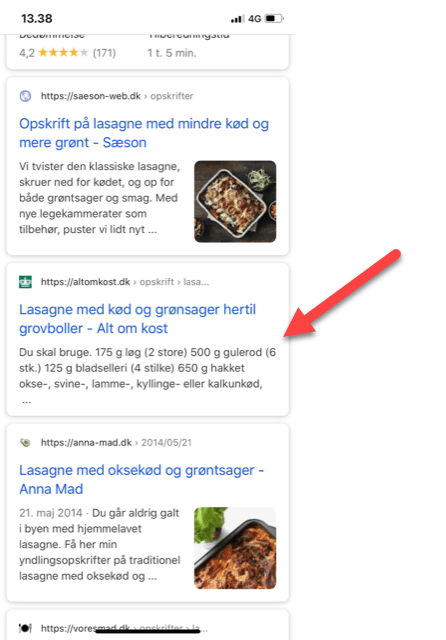
Hvis de skal identificeres manuelt, så mister man hurtigt gnisten.
Hvis man vælger at ignorere det, så mister man en gylden mulighed for at øge sin CTR.
Løsningen er:
Søgeord som ranker på side 1 på mobilen + Scrape Google for disse søgeord + Python script til at identificere manglende thumbnails for disse søgeord = WIN!
Efter at have udvalgt de vigtigste søgeord så scraper vi side 1 på Google for hvert udvalgt søgeord. Det gør vi via vores dataleverandør Authoritas.
Authoritas er i samme liga som Serpwoo som samarbejdspartner. En klar anbefaling. Et eksempel på samarbejdet er, at vi faktisk manglede thumbnails data i deres API. De ændrede deres API få dage efter, at vi spurgte ind til det.

Ligesom i det foregående eksempel kan det godt tage 5-7 timer at trække data. Når vi har trukket data og merget med GSC data (f.eks. i Power BI) får vi et overblik over, hvilke søgeord, hvor der ikke bliver vist image thumbnails på mobilen.
Det næste skridt er at få vist et image thumbnail, hvor jeg har fundet en original metode til at få den vist. En metode som gik twitter-amok, da den antyder vigtigheden af, at billedebeskrivelser er vigtige.
Her er et praktisk eksempel:
Når jeg søger på “behagelige bukser”, vises der ikke noget billede for Wagner.dk.
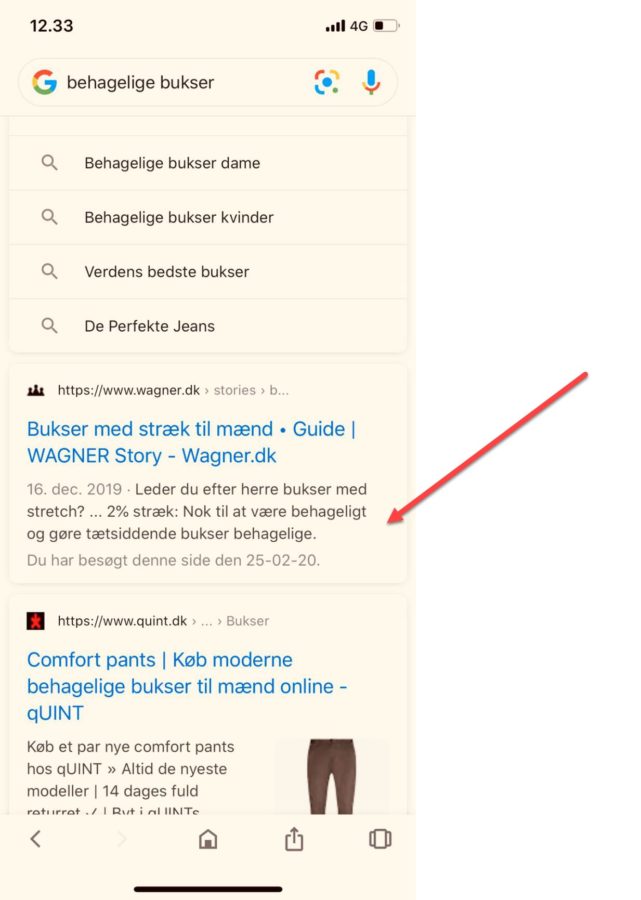
Først eksperimenterede jeg med at indsætte mit søgeord i alt tagget.
Intet skete.
Derefter indsatte jeg også søgeordet i title tagget.
Voila!
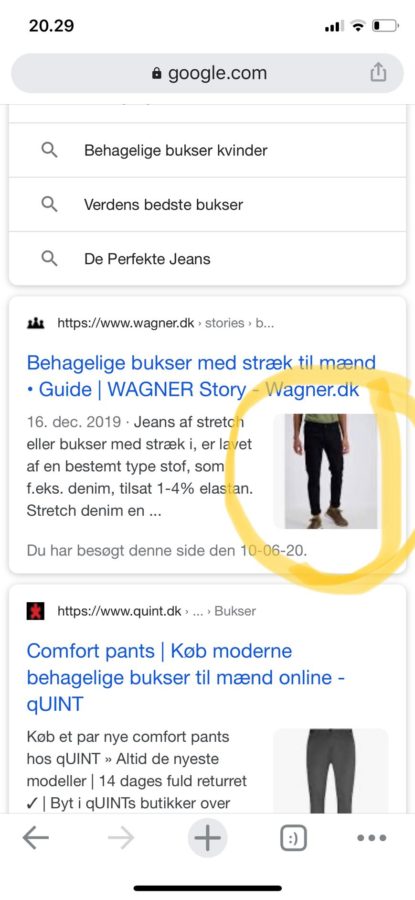
Nu bliver der vist et image thumbnail i resultatet.
Hvad betød det for søgeordet “behagelige bukser”?
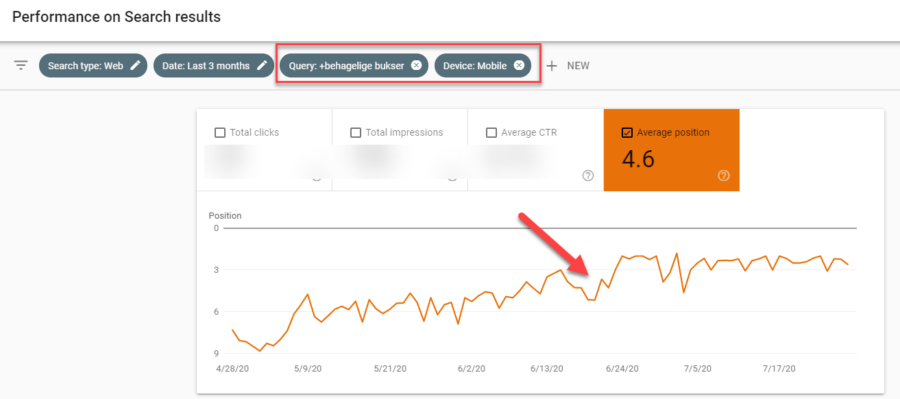
Efter at det lykkedes at få vist thumbnail, strøg wagner.dk op som nr. 2 på Google. Om det skyldtes tekstoptimeringen, en højere CTR grundet thumbnailet, en kombination eller en helt fjerde grund er ikke til at sige.
Da vi så, at det virkede, optimerede vi efterfølgende for de resterende 136 søgeord på samme domæne, hvor der ikke blev vist image thumbnails.
Resultat:
– Det lykkedes os at få vist image thumbnails for 45 af de 136 søgeord indenfor en måned.
1. Opret en .txt fil indeholdende de søgeord, som du gerne vil tjekke for manglende image thumbnail på mobilresultater.
2. Kør første script med følgende linje: python send_queries.py –input your_queries.txt
3. Efter at det første script er kørt, skal du vente et par timer og køre næste script (dette skyldes, at vi ligger i kø). Brug følgende linje og outputtet af filen med JOB-IDs fra første script til at køre næste script med: python get_results.py –input job_ids.csv
4. Data vil blive spyttet ud i en CSV-fil indeholdende en kolonne med navnet Thumbnail, som viser TRUE, hvis der allerede er et image thumbnail for søgeordet.
Script 1:
import requests
import time
import hmac
import hashlib
import base64
import json
import argparse
import csv
from configparser import ConfigParser
if __name__ == ‘__main__’:
parser = argparse.ArgumentParser()
parser.add_argument(‘-i’, ‘–input’, type=str, required=True,
help=’Input file (one query per line).’)
parser.add_argument(‘-o’, ‘–output’, type=str, default=’queries’,
help=’Output file basename (default: queries).’)
parser.add_argument(‘–sep’, type=str, default=’;’,
help=’Output CSV separator (default: “;”).’)
parser.add_argument(‘-n’, ‘–nb_res’, type=int, default=20,
help=’Number of results to fetch (default: 20).’)
parser.add_argument(‘-r’, ‘–region’, type=str, default=’dk’,
choices=[‘global’,’fr’,’gb’,’us’,’es’,’dk’],
help=’Region (default: dk).’)
parser.add_argument(‘-l’, ‘–language’, type=str, default=’da’,
choices=[‘en’,’fr’,’es’,’da’],
help=’Language (default: da).’)
parser.add_argument(‘-s’, ‘–search_engine’, type=str, default=’google’,
choices=[‘google’,’bing’,’yahoo’,’yandex’,’baidu’],
help=’Search Engine (default: google).’)
parser.add_argument(‘-u’, ‘–user_agent’, type=str, default=’mobile’,
choices=[‘pc’,’mac’,’tablet’,’ipad’,’iphone’,’mobile’],
help=’User Agent choice (default: mobile).’)
parser.add_argument(‘–no_cache’, action=’store_true’, default=False,
help=’Do not use query cache (default: False).’)
parser.add_argument(‘-d’, ‘–delay’, type=int, default=4,
help=’Delay in seconds between requests (default: 4).’)
args = parser.parse_args()
# Get API settings from config.ini file
config = ConfigParser()
config.read(‘config.ini’)
host = config.get(‘AUTHORITAS_API’,’host’)
private_key = config.get(‘AUTHORITAS_API’,’private_key’)
public_key = config.get(‘AUTHORITAS_API’,’public_key’)
salt = config.get(‘AUTHORITAS_API’,’salt’)
kws = list()
# Read list of requests
with open(args.input,’r’, encoding=’utf-8′) as file:
for line in file.readlines():
kws.append(str.strip(line))
file.close()
# Output name
timestr = time.strftime(“%Y%m%d-%H%M%S”)
filename = args.output + “-” + timestr + “.csv”
output_headers = [‘query’,’jid’]
with open(filename,’w’,newline=”) as file:
writer = csv.DictWriter(file, fieldnames=output_headers, delimiter=args.sep)
writer.writeheader()
file.close()
for kw in kws:
# Generate a unix timestamp to insert into headers
now = int(time.time())
# Generate headers
hash_data = “{}{}{}”.format(now, public_key, salt)
hashed = hmac.new(private_key.encode(“utf-8”), hash_data.encode(“utf-8”), hashlib.sha256).hexdigest()
headers = {
‘accept’: “application/json”,
‘Authorization’: “KeyAuth publicKey={} hash={} ts={}”.format(public_key,hashed,now)
}
# Request body
body = {
“search_engine”:args.search_engine,
“region”:args.region,
“language”:args.language,
“max_results”:args.nb_res,
“phrase”:kw
}
if args.no_cache:
body[‘use_cache’] = False
url = ‘{}/search_results/’.format(host)
r = requests.post(url, data=json.dumps(body), headers=headers)
with open(filename,’a’,newline=”) as file:
writer = csv.DictWriter(file, fieldnames=output_headers, delimiter=args.sep)
writer.writerow({
‘query’: kw,
‘jid’: r.json().get(‘jid’)
})
file.close()
print(‘Request {} created (jid: {}).’.format(kw,r.json().get(‘jid’)))
time.sleep(args.delay)
Script 2:
import requests
import time
import hmac
import hashlib
import base64
import json
import argparse
import csv
import configparser
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument(‘-i’, ‘–input’, type=str, required=True,
help=’Input CSV file (needs columns query and jid).’)
parser.add_argument(‘–input_sep’, type=str, default=’;’,
help=’Input CSV separator (default: “;”).’)
parser.add_argument(‘-o’, ‘–output’, type=str, default=’results’,
help=’Output file basename (default: results).’)
parser.add_argument(‘–sep’, type=str, default=’;’,
help=’Output CSV separator (default: “;”).’)
parser.add_argument(‘-d’, ‘–delay’, type=int, default=4,
help=’Delay in seconds between requests (default: 4).’)
args = parser.parse_args()
# Get API settings from config.ini file
config = configparser.ConfigParser()
config.read(‘config.ini’)
host = config.get(‘AUTHORITAS_API’,’host’)
private_key = config.get(‘AUTHORITAS_API’,’private_key’)
public_key = config.get(‘AUTHORITAS_API’,’public_key’)
salt = config.get(‘AUTHORITAS_API’,’salt’)
# Output name
timestr = time.strftime(“%Y%m%d-%H%M%S”)
timestr1 = time.strftime(“%Y%m%d”)
filename = args.output + “-” + timestr + “.csv”
output_headers = [‘query’,’jid’,’status’,’position’,’page’,’url’,’title’,’above_the_fold’,’top_left_x’,’top_left_y’,’bottom_right_x’,’bottom_right_y’,’description’,’type’,’rich_snippets’,’thumbnail’,’timestamp’]
with open(filename,’w’,newline=”, encoding=’utf-8′) as output_file:
writer = csv.DictWriter(output_file, fieldnames=output_headers, delimiter=args.sep)
writer.writeheader()
output_file.close()
with open(args.input,’r’) as input_file:
reader = csv.DictReader(input_file, delimiter=args.input_sep)
for row in reader:
kw = row[‘query’]
jid = row[‘jid’]
# Generate a unix timestamp to insert into headers
now = int(time.time())
# Generate headers
hash_data = “{}{}{}”.format(now, public_key, salt)
hashed = hmac.new(private_key.encode(“utf-8”), hash_data.encode(“utf-8”), hashlib.sha256).hexdigest()
headers = {
‘accept’: “application/json”,
‘Authorization’: “KeyAuth publicKey={} hash={} ts={}”.format(public_key,hashed,now)
}
url = ‘{}/search_results/{}’.format(host,jid)
# Get data
r = requests.get(url, headers=headers)
with open(filename,’a’,newline=”, encoding=’utf-8′) as output_file:
writer = csv.DictWriter(output_file, fieldnames=output_headers, delimiter=args.sep)
if r.status_code == 200:
try:
response = json.loads(r.content)[‘response’][‘results’]
for key in response[‘organic’].keys():
topleft = response[‘organic’][key][‘top_left’].split(‘,’)
bottomright = response[‘organic’][key][‘bottom_right’].split(‘,’)
writer.writerow({
‘query’: kw,
‘jid’: jid,
‘status’: ‘ok’,
‘position’: key,
‘page’: response[‘organic’][key][‘page_number’],
‘url’: response[‘organic’][key][‘url’],
‘title’: response[‘organic’][key][‘title’],
‘above_the_fold’: response[‘organic’][key][‘above_the_fold’],
‘top_left_x’: topleft[0],
‘top_left_y’: topleft[1],
‘bottom_right_x’: bottomright[0],
‘bottom_right_y’: bottomright[1],
‘description’: response[‘organic’][key][‘description’],
‘type’: ‘organic’,
‘rich_snippets’: response[‘organic’][key][‘rich_snippets’],
‘thumbnail’: response[‘organic’][key][‘thumbnail’],
‘timestamp’: timestr1,
})
print(‘Query “{}” OK (jid: {}).’.format(kw,jid))
# Some ‘200-OK’ responses don’t have real data
except KeyError:
writer.writerow({
‘query’: kw,
‘jid’: jid,
‘status’: ‘error’,
})
print(‘Error for query “{}” (jid: {}).’.format(kw,jid))
else:
writer.writerow({
‘query’: kw,
‘jid’: jid,
‘status’: r.status_code,
})
print(‘Error for query “{}” (jid: {}).’.format(kw,jid))
output_file.close()
time.sleep(args.delay)
input_file.close()
OPSUMMERING
Jeg håber, at du har fået blod på tanden til ikke at opgive de “umulige SEO-opgaver” på forhånd. I stedet skal du prøve at automatisere dem med et Python script. Jeg vil anbefale, at du tester vores eksempel 1 først, da det er den nemmeste måde at komme i gang på.
Python og lignende værktøjer er kommet for at blive. For os som arbejder med digital marketing (Paid social, PPC, SEO etc.) til dagligt, vil det være et uvurderligt værktøj fremadrettet. Kodning og automatisering er vigtige skills for fremtidens marketers – så du kan lige så godt komme i gang med at lære det i dag!





